Summer Certification Limited Time 70% Discount Offer - Ends in 0d 00h 00m 00s - Coupon code = getmirror
Pass the Databricks Certification Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 Questions and answers with ExamsMirror
Exam Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 Premium Access
View all detail and faqs for the Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 exam
807 Students Passed
85% Average Score
96% Same Questions
A developer wants to test Spark Connect with an existing Spark application.
What are the two alternative ways the developer can start a local Spark Connect server without changing their existing application code? (Choose 2 answers)
Which command overwrites an existing JSON file when writing a DataFrame?
A data engineer is working ona Streaming DataFrame streaming_df with the given streaming data:
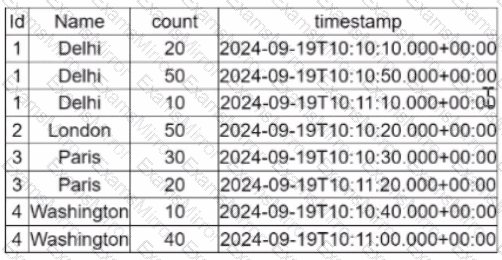
Which operation is supported with streamingdf ?
Given this code:

.withWatermark("event_time","10 minutes")
.groupBy(window("event_time","15 minutes"))
.count()
What happens to data that arrives after the watermark threshold?
Options:
An engineer notices a significant increase in the job execution time during the execution of a Spark job. After some investigation, the engineer decides to check the logs produced by the Executors.
How should the engineer retrieve the Executor logs to diagnose performance issues in the Spark application?
Which configuration can be enabled to optimize the conversion between Pandas and PySpark DataFrames using Apache Arrow?
A data engineer observes that an upstream streaming source sends duplicate records, where duplicates share the same key and have at most a 30-minute difference inevent_timestamp. The engineer adds:
dropDuplicatesWithinWatermark("event_timestamp", "30 minutes")
What is the result?
Given the following code snippet inmy_spark_app.py:

What is the role of the driver node?
A Spark engineer is troubleshooting a Spark application that has been encountering out-of-memory errors during execution. By reviewing the Spark driver logs, the engineer notices multiple "GC overhead limit exceeded" messages.
Which action should the engineer take to resolve this issue?
A data scientist has identified that some records in the user profile table contain null values in any of the fields, and such records should be removed from the dataset before processing. The schema includes fields like user_id, username, date_of_birth, created_ts, etc.
The schema of the user profile table looks like this:

Which block of Spark code can be used to achieve this requirement?
Options:
TOP CODES
Top selling exam codes in the certification world, popular, in demand and updated to help you pass on the first try.