Summer Certification Limited Time 70% Discount Offer - Ends in 0d 00h 00m 00s - Coupon code = getmirror
Pass the Google Machine Learning Engineer Professional-Machine-Learning-Engineer Questions and answers with ExamsMirror
Exam Professional-Machine-Learning-Engineer Premium Access
View all detail and faqs for the Professional-Machine-Learning-Engineer exam
636 Students Passed
97% Average Score
94% Same Questions
You need to train a computer vision model that predicts the type of government ID present in a given image using a GPU-powered virtual machine on Compute Engine. You use the following parameters:
• Optimizer: SGD
• Image shape = 224x224
• Batch size = 64
• Epochs = 10
• Verbose = 2
During training you encounter the following error: ResourceExhaustedError: out of Memory (oom) when allocating tensor. What should you do?
You need to train a natural language model to perform text classification on product descriptions that contain millions of examples and 100,000 unique words. You want to preprocess the words individually so that they can be fed into a recurrent neural network. What should you do?
Your team has been tasked with creating an ML solution in Google Cloud to classify support requests for one of your platforms. You analyzed the requirements and decided to use TensorFlow to build the classifier so that you have full control of the model's code, serving, and deployment. You will use Kubeflow pipelines for the ML platform. To save time, you want to build on existing resources and use managed services instead of building a completely new model. How should you build the classifier?
You are building a custom image classification model and plan to use Vertex Al Pipelines to implement the end-to-end training. Your dataset consists of images that need to be preprocessed before they can be used to train the model. The preprocessing steps include resizing the images, converting them to grayscale, and extracting features. You have already implemented some Python functions for the preprocessing tasks. Which components should you use in your pipeline'?
Options:
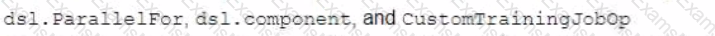
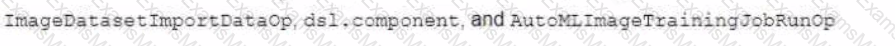
You developed a Vertex Al ML pipeline that consists of preprocessing and training steps and each set of steps runs on a separate custom Docker image Your organization uses GitHub and GitHub Actions as CI/CD to run unit and integration tests You need to automate the model retraining workflow so that it can be initiated both manually and when a new version of the code is merged in the main branch You want to minimize the steps required to build the workflow while also allowing for maximum flexibility How should you configure the CI/CD workflow?
You have recently trained a scikit-learn model that you plan to deploy on Vertex Al. This model will support both online and batch prediction. You need to preprocess input data for model inference. You want to package the model for deployment while minimizing additional code What should you do?
You work for a company that is developing an application to help users with meal planning You want to use machine learning to scan a corpus of recipes and extract each ingredient (e g carrot, rice pasta) and each kitchen cookware (e.g. bowl, pot spoon) mentioned Each recipe is saved in an unstructured text file What should you do?
You work for an online travel agency that also sells advertising placements on its website to other companies.
You have been asked to predict the most relevant web banner that a user should see next. Security is
important to your company. The model latency requirements are 300ms@p99, the inventory is thousands of web banners, and your exploratory analysis has shown that navigation context is a good predictor. You want to Implement the simplest solution. How should you configure the prediction pipeline?
You recently deployed a model to a Vertex Al endpoint Your data drifts frequently so you have enabled request-response logging and created a Vertex Al Model Monitoring job. You have observed that your model is receiving higher traffic than expected. You need to reduce the model monitoring cost while continuing to quickly detect drift. What should you do?
You have developed an application that uses a chain of multiple scikit-learn models to predict the optimal price for your company's products. The workflow logic is shown in the diagram Members of your team use the individual models in other solution workflows. You want to deploy this workflow while ensuring version control for each individual model and the overall workflow Your application needs to be able to scale down to zero. You want to minimize the compute resource utilization and the manual effort required to manage this solution. What should you do?
TOP CODES
Top selling exam codes in the certification world, popular, in demand and updated to help you pass on the first try.