Summer Certification Limited Time 70% Discount Offer - Ends in 0d 00h 00m 00s - Coupon code = getmirror
Pass the Workday Integrations Workday-Pro-Integrations Questions and answers with ExamsMirror
Exam Workday-Pro-Integrations Premium Access
View all detail and faqs for the Workday-Pro-Integrations exam
739 Students Passed
84% Average Score
92% Same Questions
Refer to the following scenario to answer the question below.
You have been asked to build an integration using the Core Connector: Worker template and should leverage the Data Initialization Service (DIS). The integration will be used to export a full file (no change detection) for employees only and will include personal data.
What configuration is required to ensure that when outputting phone number only the home phone number is included in the output?
Options:
Configure an integration map to map the phone type.
Include the phone type integration field attribute.
Configure the phone type integration attribute.
Configure an integration field override to include phone type.
The scenario involves a Core Connector: Worker integration using DIS to export a full file of employee personal data, with the requirement to output only the home phone number when including phone data. Workday’s "Phone Number" field is multi-instance, meaning a worker can have multiple phone types (e.g., Home, Work, Mobile). Let’s determine the configuration:
Requirement:Filter the multi-instance "Phone Number" field to include only the "Home" phone number in the output file. This involves specifying which instance of the phone data to extract.
Integration Field Attributes:In Core Connectors,Integration Field Attributesallow you to refine how multi-instance fields are handled in the output. For the "Phone Number" field, you can set an attribute like "PhoneType" to "Home" to ensure only home phone numbers are included. This is a field-level configuration that filters instances without requiring a calculated field or override.
Option Analysis:
A. Configure an integration map to map the phone type: Incorrect. Integration Maps transform field values (e.g., "United States" to "USA"), not filter multi-instance data like selecting a specific phone type.
B. Include the phone type integration field attribute: Correct. This configures the "Phone Number" field to output only instances where the phone type is "Home," directly meeting the requirement.
C. Configure the phone type integration attribute: Incorrect. "Integration attribute" refers to integration-level settings (e.g., file format), not field-specific configurations. The correct term is "integration field attribute."
D. Configure an integration field override to include phone type: Incorrect. Integration Field Overrides are used to replace a field’s value with a calculated field or custom value, not to filter multi-instance data like phone type.
Implementation:
Edit the Core Connector: Worker integration.
Navigate to theIntegration Field Attributessection for the "Phone Number" field.
Set the "Phone Type" attribute to "Home" (or equivalent reference ID for Home phone).
Test the output file to confirm only home phone numbers are included.
References from Workday Pro Integrations Study Guide:
Core Connectors & Document Transformation: Section on "Integration Field Attributes" explains filtering multi-instance fields like phone numbers by type.
Integration System Fundamentals: Notes how Core Connectors handle multi-instance data with field-level attributes.
What is the purpose of a namespace in the context of a stylesheet?
Options:
Provides elements you can use in your code.
Indicates the start and end tag names to output.
Restricts the data the processor can access.
Controls the filename of the transformed result.
In the context of a stylesheet, particularly within Workday's Document Transformation system where XSLT (Extensible Stylesheet Language Transformations) is commonly used, anamespaceserves a critical role in defining the scope and identity of elements and attributes. The correct answer, as aligned with Workday’s integration practices and standard XSLT principles, is that a namespace "provides elements you can use in your code." Here’s a detailed explanation:
Definition and Purpose of a Namespace:
A namespace in an XML-based stylesheet (like XSLT) is a mechanism to avoid naming conflicts by grouping elements and attributes under a unique identifier, typically a URI (Uniform Resource Identifier). This allows different vocabularies or schemas to coexist within the same document or transformation process without ambiguity.
In XSLT, namespaces are declared in the stylesheet using the xmlns attribute (e.g., xmlns:xsl="http://www.w3.org/1999/XSL/Transform" for XSLT itself). These declarations define the set of elements and functions available for use in the stylesheet, such as
For example, when transforming Workday data (which uses its own XML schema), a namespace might be defined to reference Workday-specific elements, enabling the stylesheet to correctly identify and manipulate those elements.
Application in Workday Context:
In Workday’s Document Transformation integrations, namespaces are essential when processing XML data from Workday (e.g., Core Connector outputs) or external systems. The namespace ensures that the XSLT processor recognizes the correct elements from the source XML and applies the transformation rules appropriately.
Without a namespace, the processor might misinterpret elements with the same name but different meanings (e.g.,
Why Other Options Are Incorrect:
B. Indicates the start and end tag names to output: This is incorrect because namespaces do not dictate the structure (start and end tags) of the output. That is determined by the XSLT template rules and output instructions (e.g.,
C. Restricts the data the processor can access: While namespaces help distinguish between different sets of elements, they do not inherently restrict data access. Restrictions are more a function of security settings or XPath expressions within the stylesheet, not the namespace itself.
D. Controls the filename of the transformed result: Namespaces have no bearing on the filename of the output. In Workday, the filename of a transformed result is typically managed by the Integration Attachment Service or delivery settings (e.g., SFTP or email configurations), not the stylesheet’s namespace.
Practical Example:
Suppose you’re transforming a Workday XML file containing employee data into a custom format. The stylesheet might include:
Here, the wd namespace provides access to Workday-specific elements like
Workday Pro Integrations Study Guide References:
Workday Integration System Fundamentals: Explains XML and XSLT basics, including the role of namespaces in identifying elements within stylesheets.
Document Transformation Module: Highlights how namespaces are used in XSLT to process Workday XML data, emphasizing their role in providing a vocabulary for transformation logic (e.g., "Understanding XSLT Namespaces").
Core Connectors and Document Transformation Course Manual: Includes examples of XSLT stylesheets where namespaces are declared to handle Workday-specific schemas, reinforcing that they provide usable elements.
Workday Community Documentation: Notes that namespaces are critical for ensuring compatibility between Workday’s XML output and external system requirements in transformation scenarios.
Refer to the following XML data source to answer the question below.
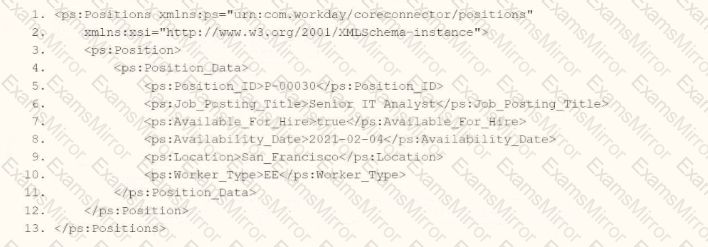
You need the integration file to format the ps:Position_ID field to 10 characters, truncate the value if it exceeds, and align everything to the left.
How will you start your template match on ps:Position to use Document Transformation (DT) to do the transformation using XTT?
Options:




In Workday integrations, Document Transformation (DT) using XSLT with Workday Transformation Toolkit (XTT) attributes is used to transform XML data, such as the output from a Core Connector or EIB, into a specific format for third-party systems. In this scenario, you need to transform the ps:Position_ID field within the ps:Position element to a fixed length of 10 characters, truncate the value if it exceeds 10 characters, and align the output to the left. The template must match the ps:Position element and apply these formatting rules using XTT attributes.
Here’s why option A is correct:
Template Matching: The
XTT Attributes:
xtt:fixedLength="10" specifies that the Pos_ID field should be formatted to a fixed length of 10 characters. If the ps:Position_ID value exceeds 10 characters, it will be truncated (by default, XTT truncates without raising an error unless explicitly configured otherwise), meeting the requirement to truncate if the value exceeds.
xtt:align="left" ensures that the output is left-aligned within the 10-character field, aligning with the requirement to align everything to the left.
XPath Selection: The
Output Structure: The
Why not the other options?
B.
xml
WrapCopy
This applies xtt:align="left" to the xsl:template element instead of the Pos_ID element. XTT attributes like fixedLength and align must be applied directly to the element being formatted (Pos_ID), not the template itself, making this incorrect.
C.
xml
WrapCopy
This applies xtt:fixedLength="10" to the Position element and xtt:align="left" to Pos_ID. However, XTT attributes like fixedLength and align should be applied to the specific field being formatted (Pos_ID), not the parent element (Position). This misplacement makes it incorrect.
D.
xml
WrapCopy
This applies xtt:fixedLength="10" to the xsl:template element and xtt:align="left" to Pos_ID. Similar to option B, XTT attributes must be applied to the specific element (Pos_ID) being formatted, not the template itself, making this incorrect.
To implement this in XSLT for a Workday integration:
Use the template from option A to match ps:Position, apply xtt:fixedLength="10" and xtt:align="left" to the Pos_ID element, and extract the ps:Position_ID value using the correct XPath. This ensures the ps:Position_ID (e.g., "P-00030") is formatted to 10 characters, truncated if necessary, and left-aligned, meeting the integration file requirements.
References:
Workday Pro Integrations Study Guide: Section on "Document Transformation (DT) and XTT" – Details the use of XTT attributes like fixedLength and align for formatting data in XSLT transformations, including truncation behavior.
Workday Core Connector and EIB Guide: Chapter on "XML Transformations" – Explains how to use XSLT templates with XTT attributes to transform position data, including fixed-length formatting and alignment.
Workday Integration System Fundamentals: Section on "XTT in Integrations" – Covers the application of XTT attributes to specific fields in XML for integration outputs, ensuring compliance with formatting requirements like length and alignment.
You need to create a report that includes data from multiple business objects. For a supervisory organization specified at run time, the report must output one row per worker, their active benefit plans, and the names and ages of all related dependents. The Worker business object contains the Employee, Benefit Plans, and Dependents fields. The Dependent business object contains the employee's dependent's Name and Age fields.
How would you select the primary business object (PBO) and related business objects (RBO) for the report?
Options:
PBO: Dependent, RBO: Worker
PBO: Worker, RBO: Dependent
PBO: Dependent, no RBOs
PBO: Worker; no RBOs
In Workday reporting, selecting the appropriatePrimary Business Object (PBO)andRelated Business Objects (RBOs)is critical to ensure that the report retrieves and organizes data correctly based on the requirements. The requirement here is to create a report that outputs one row per worker for a specified supervisory organization, including their active benefit plans and the names and ages of all related dependents. The Worker business object contains fields like Employee, Benefit Plans, and Dependents, while the Dependent business object provides the Name and Age fields for dependents.
Why Worker as the PBO?The report needs to output "one row per worker," making the Worker business object the natural choice for the PBO. In Workday, the PBO defines the primary dataset and determines the granularity of the report (i.e., one row per instance of the PBO). Since the report revolves around workers and their associated data (benefit plans and dependents), Worker is the starting point. Additionally, the requirement specifies a supervisory organization at runtime, which is a filter applied to the Worker business object to limit the population.
Why Dependent as an RBO?The Worker business object includes a "Dependents" field, which is a multi-instance field linking to the Dependent business object. To access detailed dependent data (Name and Age), the Dependent business object must be added as an RBO. This allows the report to pull in the related dependent information for each worker. Without the Dependent RBO, the report could only reference the existence of dependents, not their specific attributes like Name and Age.
Analysis of Benefit Plans:The Worker business object already contains the "Benefit Plans" field, which provides access to active benefit plan data. Since this is a field directly available on the PBO (Worker), no additional RBO is needed to retrieve benefit plan information.
Option Analysis:
A. PBO: Dependent, RBO: Worker: Incorrect. If Dependent were the PBO, the report would output one row per dependent, not one row per worker, which contradicts the requirement. Additionally, Worker as an RBO would unnecessarily complicate accessing worker-level data.
B. PBO: Worker, RBO: Dependent: Correct. This aligns with the requirement: Worker as the PBO ensures one row per worker, and Dependent as the RBO provides access to dependent details (Name and Age). Benefit Plans are already accessible via the Worker PBO.
C. PBO: Dependent, no RBOs: Incorrect.This would result in one row per dependent and would not allow easy access to worker or benefit plan data, failing to meet the "one row per worker" requirement.
D. PBO: Worker, no RBOs: Incorrect. While Worker as the PBO is appropriate, omitting the Dependent RBO prevents the report from retrieving dependent Name and Age fields, which are stored in the Dependent business object, not directly on Worker.
Implementation:
Create a custom report withWorkeras the PBO.
Add a filter for the supervisory organization (specified at runtime) on the Worker PBO.
AddDependentas an RBO to access Name and Age fields.
Include columns from Worker (e.g., Employee, Benefit Plans) and Dependent (e.g., Name, Age).
References from Workday Pro Integrations Study Guide:
Workday Report Writer Fundamentals: Section on "Selecting Primary and Related Business Objects" explains how the PBO determines the report’s row structure and RBOs extend data access to related objects.
Integration System Fundamentals: Discusses how multi-instance fields (e.g., Dependents on Worker) require RBOs to retrieve detailed attributes.
Refer to the following XML to answer the question below.

You are an integration developer and need to write XSLT to transform the output of an EIB which is making a request to the Get Job Profiles web service operation. The root template of your XSLT matches on the
What XPath syntax would be used to select the value of the wd:Job_Code element when the
Options:
wd:Job_Profile/wd:Job_Profile_Data/wd:Job_Code
wd:Job_Profile_Data[@wd:Job_Code]
wd:Job_Profile_Data/wd:Job_Code
wd:Job_Profile_Reference/wd:ID[@wd:type='Job_Profile_ID']
As an integration developer working with Workday, you are tasked with transforming the output of an Enterprise Interface Builder (EIB) that calls the Get_Job_Profiles web service operation. The provided XML shows the response from this operation, and you need to write XSLT to select the value of the
Understanding the XML and Requirement
The XML snippet provided is a SOAP response from the Get_Job_Profiles web service operation in Workday, using the namespace xmlns:wd="urn:com.workday/bsvc" and version wd:version="v43.0". Key elements relevant to the question include:
The root element is
It contains
Within
The task is to select the value of
Analysis of Options
Let’s evaluate each option based on the XML structure and XPath syntax rules:
Option A: wd:Job_Profile/wd:Job_Profile_Data/wd:Job_Code
This XPath starts from wd:Job_Profile and navigates to wd:Job_Profile_Data/wd:Job_Code. However, in the XML,
However, since the template matches
Option B: wd:Job_Profile_Data[@wd:Job_Code]
This XPath uses an attribute selector ([@wd:Job_Code]) to filter
Option C: wd:Job_Profile_Data/wd:Job_Code
This XPath starts from wd:Job_Profile_Data (a direct child of
Concise and appropriate for the context.
Directly selects the value "Senior_Benefits_Analyst" when used with
Matches the XML structure, as
This is the most straightforward and correct option for selecting the
Option D: wd:Job_Profile_Reference/wd:ID[@wd:type='Job_Profile_ID']
This XPath navigates to
The XPath wd:Job_Profile_Reference/wd:ID[@wd:type='Job_Profile_ID'] selects the
Why Option C is Correct
Option C, wd:Job_Profile_Data/wd:Job_Code, is the correct XPath syntax because:
It starts from the context node
It is concise and aligns with standard XPath navigation in XSLT, avoiding unnecessary redundancy (unlike Option A) or incorrect attribute selectors (unlike Option B).
It matches the XML structure, where
When used with
Practical Example in XSLT
Here’s how this might look in your XSLT:
xml
WrapCopy
This would output "Senior_Benefits_Analyst" for the
Verification with Workday Documentation
The Workday Pro Integrations Study Guide and SOAP API Reference (available via Workday Community) detail the structure of the Get_Job_Profiles response and how to use XPath in XSLT for transformations. The XML structure shows
Workday Pro Integrations Study Guide References
Section: XSLT Transformations in EIBs– Describes using XSLT to transform web service responses, including selecting elements with XPath.
Section: Workday Web Services– Details the Get_Job_Profiles operation and its XML output structure, including
Section: XPath Syntax– Explains how to navigate XML hierarchies in Workday XSLT, using relative paths like wd:Job_Profile_Data/wd:Job_Code from a
Workday Community SOAP API Reference – Provides examples of XPath navigation for Workday web service responses.
Option C is the verified answer, as it correctly selects the
Refer to the following XML and example transformed output to answer the question below.

Example transformed wd:Report_Entry output;

What is the XSLT syntax tor a template that matches onwd: Educationj3roup to produce the degree data in the above Transformed_Record example?
Options:




In Workday integrations, XSLT is used to transform XML data, such as the output from a web service-enabled report or EIB, into a desired format for third-party systems. In this scenario, you need to create an XSLT template that matches the wd:Education_Group element in the provided XML and transforms it to produce the degree data in the format shown in the Transformed_Record example. The goal is to output each degree (e.g., "California University MBA" and "Georgetown University B.S.") as a
Here’s why option A is correct:
Template Matching: The
Transformation Logic:
This approach ensures that each wd:Education_Group is transformed into a single
Context and Output: The template operates on each wd:Education_Group, producing the nested structure shown in the Transformed_Record (e.g.,
Why not the other options?
B.
xml
WrapCopy
This uses
C.
xml
WrapCopy
This uses
D.
xml
WrapCopy
This uses
To implement this in XSLT for a Workday integration:
Use the template from option A to match wd:Education_Group, apply
References:
Workday Pro Integrations Study Guide: Section on "XSLT Transformations for Workday Integrations" – Details the use of
Workday EIB and Web Services Guide: Chapter on "XML and XSLT for Report Data" – Explains the structure of Workday XML (e.g., wd:Education_Group, wd:Education, wd:Degree) and how to use XSLT to transform education data into a flattened format.
Workday Reporting and Analytics Guide: Section on "Web Service-Enabled Reports" – Covers integrating report outputs with XSLT for transformations, including examples of concatenating and restructuring data for third-party systems.
What task is needed to build a sequence generator for an EIB integration?
Options:
Put Sequence Generator Rule Configuration
Create ID Definition/Sequence Generator
Edit Tenant Setup - Integrations
Configure Integration Sequence Generator Service
In Workday, a sequence generator is used to create unique, sequential identifiers for integration processes, such as Enterprise Interface Builders (EIBs). These identifiers are often needed to ensure data uniqueness or to meet external system requirements for tracking records. The question asks specifically about building a sequence generator for an EIB integration, so we need to identify the correct task based on Workday’s integration configuration framework.
Understanding Sequence Generators in Workday
A sequence generator in Workday generates sequential numbers or IDs based on predefined rules, such as starting number, increment, and format. These are commonly used in integrations to create unique identifiers for outbound or inbound data, ensuring consistency and compliance with external system requirements. For EIB integrations, sequence generators are typically configured as part of the integration setup to handle data sequencing or identifier generation.
Analyzing the Options
Let’s evaluate each option to determine which task is used to build a sequence generator for an EIB integration:
A. Put Sequence Generator Rule Configuration
Description: This option suggests configuring rules for a sequence generator, but "Put Sequence Generator Rule Configuration" is not a standard Workday task name or functionality. Workday uses specific nomenclature like "Create ID Definition/Sequence Generator" for sequence generator setup. This option seems vague or incorrect, as it doesn’t align with Workday’s documented tasks for sequence generators.
Why Not Correct?: It’s not a recognized Workday task, and sequence generator configuration is typically handled through a specific setup process, not a "put" or rule-based configuration in this context.
B. Create ID Definition/Sequence Generator
Description: This is a standard Workday task used to create and configure sequence generators. In Workday, you navigate to the "Create ID Definition/Sequence Generator" task under the Integrations or Setup domain to define a sequence generator. This task allows you to specify the starting number, increment, format (e.g., numeric, alphanumeric), and scope (e.g., tenant-wide or integration-specific). For EIB integrations, this task is used to generate unique IDs or sequences for data records.
Why Correct?: This task directly aligns with Workday’s documentation for setting up sequence generators, as outlined in integration guides. It’s the standard method for building a sequence generator for use in EIBs or other integrations.
C. Edit Tenant Setup - Integrations
Description: This task involves modifying broader tenant-level integration settings, such as enabling services, configuring security, or adjusting integration parameters. While sequence generators might be used within integrations, this task is too high-level and does not specifically address creating or configuring a sequence generator.
Why Not Correct?: It’s not granular enough for sequence generator setup; it focuses on tenant-wide integration configurations rather than the specific creation of a sequence generator.
D. Configure Integration Sequence Generator Service
Description: This option suggests configuring a service specifically for sequence generation within an integration. However, Workday does not use a task named "Configure Integration Sequence Generator Service." Sequence generators are typically set up as ID definitions, not as standalone services. This option appears to be a misnomer or non-standard terminology.
Why Not Correct?: It’s not a recognized Workday task, and sequence generators are configured via "Create ID Definition/Sequence Generator," not as a service configuration.
Conclusion
Based on Workday’s integration framework and documentation, the correct task for building a sequence generator for an EIB integration isB. Create ID Definition/Sequence Generator. This task allows you to define and configure the sequence generator with the necessary parameters (e.g., starting value, increment, format) for use in EIBs. This is a standard practice for ensuring unique identifiers in integrations, as described in Workday’s Pro Integrations training materials.
Surprising Insight
It’s interesting to note that Workday’s sequence generators are highly flexible, allowing customization for various use cases, such as generating employee IDs, transaction numbers, or integration-specific sequences. The simplicity of the "Create ID Definition/Sequence Generator" task makes it accessible even for non-technical users, which aligns with Workday’s no-code integration philosophy.
Key Citations
Workday Pro Integrations Study Guide, Module 3: EIB Configuration
Workday Integration Cloud Connect: Sequence Generators
Workday EIB and Sequence Generator Overview
Configuring Workday Integrations: ID Definitions
Refer to the following XML to answer the question below.

You are an integration developer and need to write X8LT to transform the output of an ElB which is using a web service enabled report to output position data along with hiring restrictions around skills. You currently have a template which matches on wd:Report Data/wd: Report .Entry for creating a record from each report entry.
Within the template which matches on wd:Report_Entry you would like to conditionally process the wd:Job_Skills element by using a series of
Assuming all jobs will have the wd:Job_Skills element, what XSLT syntax would be used to output the text HR Skills if the value of wd:Job_Skills contains the text HR and output NON-HR Skills if the value of wd:Job_Skills does not contain the text HR?
Options:

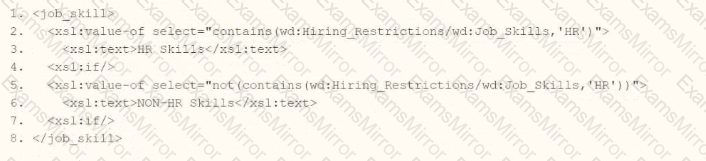
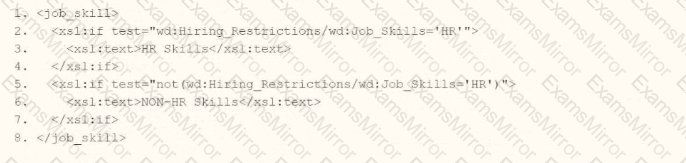
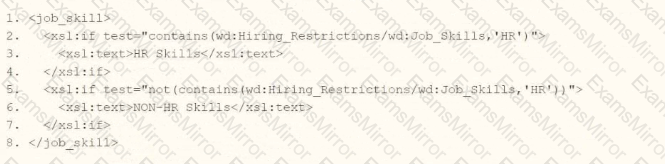
The task is to write XSLT within a template matching wd:Report_Data/wd:Report_Entry to categorize wd:Job_Skills data, outputting "HR Skills" if the value contains "HR" and "NON-HR Skills" if it does not, using a series of
Let’s analyze each option:
Option A:
xml
Issues:
The = operator checks for exact equality (e.g., wd:Job_Skills must be exactly "HR"), not substring presence, which contradicts the requirement to check if "HR" is contained within the value.
Verdict: Incorrect syntax and logic.
Option B:
xml
Issues:
Similar to A,
The
While contains() is correct for substring checking, the structure fails to meet the
Verdict: Incorrect structure despite using contains().
Option C:
xml
Analysis:
Uses
However, wd:Job_Skills='HR' tests for exact equality, not whether "HR" is contained within the value. For example, "HR Specialist" would fail this test, outputting "NON-HR Skills" incorrectly.
Verdict: Semantically incorrect due to exact matching instead of substring checking.
Option D:
xml
Analysis:
Correctly uses
The contains() function properly checks if "HR" is a substring within wd:Job_Skills (e.g., "HR Manager" or "Senior HR" returns true).
not(contains()) ensures the opposite condition, covering all cases (mutually exclusive).
Note: The closing tag is a typo in the option (should be ), but in context, it’s an obvious formatting error, not a substantive issue.
Verdict: Correct logic and syntax, making D the best answer.
Correct Implementation in Context:
xml
Example Input:
Example Input:
References:
Workday Pro Integrations Study Guide: "Configure Integration System - TRANSFORMATION" section, detailing
Workday Documentation: "XSLT Transformations in Workday" under EIB, confirming wd: namespace usage and string functions.
W3C XSLT 1.0 Specification: Section 9.1, "Conditional Processing with
Workday Community: Examples of substring-based conditionals in XSLT for report transformations.
A calculated field used as a field override in a Connector is not appearing in the output. Assuming the field has a value, what could cause this to occur?
Options:
Access not provided to calculated field data source.
Access not provided to all fields in the calculated field.
Access not provided to Connector calculated field web service.
Access not provided to all instances of calculated field.
This question addresses a troubleshooting scenario in Workday Pro Integrations, where a calculated field used as a field override in a Connector does not appear in the output, despite having a value. Let’s analyze the potential causes and evaluate each option.
Understanding Calculated Fields and Connectors in Workday
Calculated Fields:In Workday, calculated fields are custom fields created using Workday’s expression language to derive values based on other fields, conditions, or functions. They are often used in reports, integrations, and business processes to transform or aggregate data. Calculated fields can reference other fields (data sources) and require appropriate security permissions to access those underlying fields.
Field Override in Connectors:In a Core Connector or other integration system, a field override allows you to replace or supplement a default field with a custom value, such as a calculated field. This is configured in the integration’s mapping or transformation steps, ensuring the output includes the desired data. However, for the calculated field to appear in the output, it must be accessible, have a valid value, and be properly configured in the integration.
Issue: Calculated Field Not Appearing in Output:If the calculated field has a value but doesn’t appear in the Connector’s output, the issue likely relates to security, configuration, or access restrictions. The question assumes the field has a value, so we focus on permissions or setup errors rather than data issues.
Evaluating Each Option
Let’s assess each option based on Workday’s integration and security model:
Option A: Access not provided to calculated field data source.
Analysis:This is partially related but incorrect as the primary cause. Calculated fields often rely on underlying data sources (e.g., worker data, organization data) to compute their values. If access to the data source is restricted, the calculated field might not compute correctly or appear in the output. However, the question specifies the field has a value, implying the data source is accessible. The more specific issue is likely access to the individual fields within the calculated field’s expression, not just the broader data source.
Why It Doesn’t Fit:While data source access is important, it’s too general here. The calculated field’s value exists, suggesting the data source is accessible, but the problem lies in finer-grained permissions for the fields used in the calculation.
Option B: Access not provided to all fields in the calculated field.
Analysis:This is correct. Calculated fields in Workday are expressions that reference one or more fields (e.g., Worker_ID + Position_Title). For the calculated field to be used in a Connector’s output, the ISU (via its ISSG) must have access to all fields referenced in the calculation. If any field lacks "Get" or "View" permission in the relevant domain (e.g., Worker Data), the calculated field won’t appear in the output, even if it has a value. This is a common security issue in integrations, as ISSGs must be configured with domain access for every field involved.
Why It Fits:Workday’s security model requires granular permissions. For example, if a calculated field combines Worker_Name and Hire_Date, the ISU needs access to both fields’ domains. If Hire_Date is restricted, the calculated field fails to output, even with a value. This aligns with the scenario and is a frequent troubleshooting point in Workday Pro Integrations.
Option C: Access not provided to Connector calculated field web service.
Analysis:This is incorrect. There isn’t a specific "Connector calculated field web service" in Workday. Calculated fields are part of the integration’s configuration, not a separate web service. The web service operation used by the Connector (e.g., Get_Workers) must have permissions, but this relates to the overall integration, not the calculated field specifically. The issue here is field-level access, not a web service restriction.
Why It Doesn’t Fit:This option misinterprets Workday’s architecture. Calculated fields are configured within the integration, not as standalone web services, making this irrelevant to the problem.
Option D: Access not provided to all instances of calculated field.
Analysis:This is incorrect. The concept of "instances" typically applies to data records (e.g., all worker records), not calculated fields themselves. Calculated fields are expressions, not data instances, so there’s no need for "instance-level" access. The issue is about field-level permissions within the calculated field’s expression, not instances of the field. This option misunderstands Workday’s security model for calculated fields.
Why It Doesn’t Fit:Calculated fields don’t have "instances" requiring separate access; they depend on the fields they reference, making this option inaccurate.
Final Verification
The correct answer is Option B, as the calculated field’s absence in the output is likely due to the ISU lacking access to all fields referenced in the calculated field’s expression. For example, if the calculated field in a Core Connector: Worker Data combines Worker_ID and Department_Name, the ISSG must have "Get" access to both the Worker Data and Organization Data domains. If Department_Name is restricted, the calculated field won’t output, even with a value. This is a common security configuration issue in Workday integrations, addressed by reviewing and adjusting ISSG domain permissions.
This aligns with Workday’s security model, where granular permissions are required for all data elements, as seen in Questions 26 and 28. The assumption that the field has a value rules out data or configuration errors, focusing on security as the cause.
Supporting Documentation
The reasoning is based on:
Workday Community documentation on calculated fields, security domains, and integration mappings.
Tutorials on configuring Connectors and troubleshooting, such asWorkday Advanced Studio Tutorial, highlighting field access issues.
Integration security guides from partners (e.g., NetIQ, Microsoft Learn, Reco.ai) detailing ISSG permissions for fields in calculated expressions.
Community discussions on Reddit and Workday forums on calculated field troubleshooting (r/workday on Reddit).
What is the limitation when assigning ISUs to integration systems?
Options:
An ISU can be assigned to five integration systems.
An ISU can be assigned to an unlimited number of integration systems.
An ISU can be assigned to only one integration system.
An ISU can only be assigned to an ISSG and not an integration system.
This question examines the limitations on assigning Integration System Users (ISUs) to integration systems in Workday Pro Integrations. Let’s analyze the relationship and evaluate each option to determine the correct answer.
Understanding ISUs and Integration Systems in Workday
Integration System User (ISU):An ISU is a specialized user account in Workday designed for integrations, functioning as a service account to authenticate and execute integration processes. ISUs are created using the "Create Integration System User" task and are typically configured with settings like disabling UI sessions and setting long session timeouts (e.g., 0 minutes) toprevent expiration during automated processes. ISUs are not human users but are instead programmatic accounts used for API calls, EIBs, Core Connectors, or other integration mechanisms.
Integration Systems:In Workday, an "integration system" refers to the configuration or setup of an integration, such as an External Integration Business (EIB), Core Connector, or custom integration via web services. Integration systems are defined to handle data exchange between Workday and external systems, and they require authentication, often via an ISU, to execute tasks like data retrieval, transformation, or posting.
Assigning ISUs to Integration Systems:ISUs are used to authenticate and authorize integration systems to interact with Workday. When configuring an integration system, you assign an ISU to provide the credentials needed for the integration to run. This assignment ensures that the integration can access Workday data and functionalities based on the security permissions granted to the ISU via its associated Integration System Security Group (ISSG).
Limitation on Assignment:Workday’s security model imposes restrictions to maintain control and auditability. Specifically, an ISU is designed to be tied to a single integration system to ensure clear accountability, prevent conflicts, and simplify security management. This limitation prevents an ISU from being reused across multiple unrelated integration systems, reducing the risk of unintended access or data leakage.
Evaluating Each Option
Let’s assess each option based on Workday’s integration and security practices:
Option A: An ISU can be assigned to five integration systems.
Analysis:This is incorrect. Workday does not impose a specific numerical limit like "five" for ISU assignments to integration systems. Instead, the limitation is more restrictive: an ISU is typically assigned to only one integration system to ensure focused security and accountability. Allowing an ISU to serve multiple systems could lead to confusion, overlapping permissions, or security risks, which Workday’s design avoids.
Why It Doesn’t Fit:There’s no documentation or standard practice in Workday Pro Integrations suggesting a limit of five integration systems per ISU. This option is arbitrary and inconsistent with Workday’s security model.
Option B: An ISU can be assigned to an unlimited number of integration systems.
Analysis:This is incorrect. Workday’s security best practices do not allow an ISU to be assigned to an unlimited number of integration systems. Allowing this would create security vulnerabilities, as an ISU’s permissions (via its ISSG) could be applied across multiple unrelated systems, potentially leading to unauthorized access or data conflicts. Workday enforces a one-to-one or tightly controlled relationship to maintain auditability and security.
Why It Doesn’t Fit:The principle of least privilege and clear accountability in Workday integrations requires limiting an ISU’s scope, not allowing unlimited assignments.
Option C: An ISU can be assigned to only one integration system.
Analysis:This is correct. In Workday, an ISU is typically assigned to a single integration system to ensure that its credentials and permissions are tightly scoped. This aligns with Workday’s security model, where ISUs are created for specific integration purposes (e.g., an EIB, Core Connector, or web service integration). When configuring an integration system, you specify the ISU in the integration setup (e.g., under "Integration System Attributes" or "Authentication" settings), and it is not reused across multiple systems to prevent conflicts or unintended access. This limitation ensures traceability and security, as the ISU’s actions can be audited within the context of that single integration.
Why It Fits:Workday documentation and best practices, including training materials and community forums, emphasize that ISUs are dedicated to specific integrations. For example, when creating an EIB or Core Connector, you assign an ISU, and it is not shared across other integrations unless explicitly reconfigured, which is rare and discouraged for security reasons.
Option D: An ISU can only be assigned to an ISSG and not an integration system.
Analysis:This is incorrect. While ISUs are indeed assigned to ISSGs to inherit security permissions (as established in Question 26), they are also assigned to integration systems toprovide authentication and authorization for executing integration tasks. The ISU’s role includes both: it belongs to an ISSG for permissions and is linked to an integration system for execution. Saying it can only be assigned to an ISSG and not an integration system misrepresents Workday’s design, as ISUs are explicitly configured in integration systems (e.g., EIB, Core Connector) to run processes.
Why It Doesn’t Fit:ISUs are integral to integration systems, providing credentials for API calls or data exchange. Excluding assignment to integration systems contradicts Workday’s integration framework.
Final Verification
The correct answer is Option C, as Workday limits an ISU to a single integration system to ensure security, accountability, and clarity in integration operations. This aligns with the principle of least privilege, where ISUs are scoped narrowly to avoid overexposure. For example, when setting up a Core Connector: Job Postings (as in Question 25), you assign an ISU specifically for that integration, not multiple ones, unless reconfiguring for a different purpose, which is atypical.
Supporting Documentation
The reasoning is based on Workday Pro Integrations security practices, including:
Workday Community documentation on creating and managing ISUs and integration systems.
Tutorials on configuring EIBs, Core Connectors, and web services, which show assigning ISUs to specific integrations (e.g.,Workday Advanced Studio Tutorial).
Integration security overviews from implementation partners (e.g., NetIQ, Microsoft Learn, Reco.ai) emphasizing one ISU per integration for security.
Community discussions on Reddit and Workday forums reinforcing that ISUs are tied to single integrations for auditability (r/workday on Reddit).
Modal title
TOP CODES
Top selling exam codes in the certification world, popular, in demand and updated to help you pass on the first try.