Summer Certification Limited Time 70% Discount Offer - Ends in 0d 00h 00m 00s - Coupon code = getmirror
Pass the Microsoft Certified: Azure Databricks Data Engineer DP-750 Questions and answers with ExamsMirror
Exam DP-750 Premium Access
View all detail and faqs for the DP-750 exam
0 Students Passed
0% Average Score
0% Same Questions
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a managed Delta table named Table1. Table1 stores customer data.
You need to implement a data retention solution that meets the following requirements:
Deleted data must be retained for 30 days to support audits.
Deleted data that is older than 30 days must be removed permanently.
The solution must minimize administrative effort.
Which two properties should you configure? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You use Databricks Asset Bundles to manage two jobs and an app.
You need to deploy the bundle to development and production environments. The solution must meet the following requirements
• Deploy the app to both environments.
• Deploy only one job to development.
• Minimize administrative effort.
What should you use?
You need to deploy Databricks Asset Bundles to a development environment. The solution must support automated and repeatable deployments across environments.
What should you use?
You have an Azure Databricks workspace named Workspace1. You create a compute cluster named Cluser1 that will be used to ingest data.
You need to install the required libraries on Cluster 1. The solution must use Unity Catalog for access control. What should you do?
You need to complete the PySpark code for the Spark Structured Streaming pipelines. The solution must meet the data ingestion and processing requirements.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


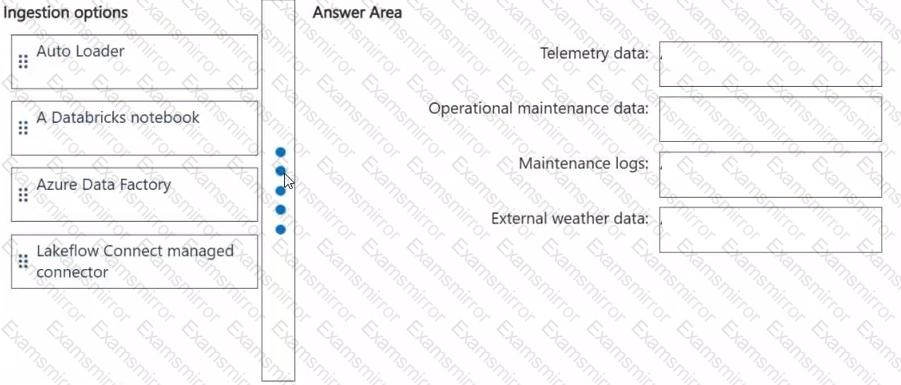
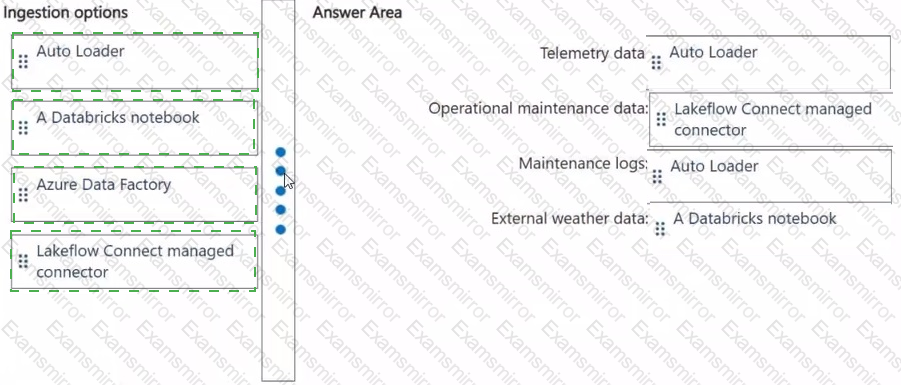
Which ingestion option should you recommend for each data source? To answer, drag the appropriate options to the correct data sources. Each option may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
You need to develop the task logic for a new job in Lakeflow Jobs that processes telemetry data.
Each task must contain only the appropriate logic for its step in the pipeline. The solution must support the planned changes and meet the data ingestion and processing requirements.
What should you do?
Which SCD type should you use to support the planned data modeling changes? To answer, drag the appropriate types to the correct issues. Each type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.


You need to configure compute for the ingestion of telemetry data. The solution must meet the data ingestion and processing requirements.
What should you do?
TOP CODES
Top selling exam codes in the certification world, popular, in demand and updated to help you pass on the first try.